


AI-Generated Code Is Creating a New Class of Vulnerabilities Nobody Is Testing For
Two months ago, Moonwell lost $1.78 million in a matter of hours.
The team had shipped a code update co-authored with Claude Opus 4.6. It had passed code review. It had unit and integration test coverage. It had also undergone a security audit by Halborn.
It still went through. The oracle priced cbETH at $1.12 instead of its actual value of around $2,200. Bots picked up the mispriced data immediately and acted on it. By the time anyone could respond, $1.78 million was gone.
This isn't an isolated incident. Similar failures are showing up across production systems with increasing frequency, and they share a pattern: AI-generated code that clears every standard check and still contains a class of error none of those checks were designed to find.
The tools aren't the problem. The testing process is.

The generator changed. The defenses didn't.
The common pushback on this topic is "just review AI code more carefully." It sounds right, but it misses the point.
Human developers make mistakes in predictable ways. They forget to sanitize an input. They copy-paste a function and miss a variable update. These are deviations from intent, and a reviewer can usually spot them because something feels off. Scanners were trained on these patterns too.
AI doesn't fail that way. AI generates code through statistical pattern completion. When Copilot writes an authentication module, it's not reasoning about what authentication means or why certain patterns are dangerous. It's producing the most plausible token sequence given your codebase and your prompt, drawn from training data that includes decades of publicly available code with all the security debt that implies.
The output is syntactically correct, functionally plausible, and sometimes subtly wrong in ways that don't look wrong. That's the hard part. Not that AI makes mistakes, but that it makes a different kind of mistake than what your current pipeline was built to catch.
In 2022, Stanford researchers ran a study where developers using AI assistants produced code with more security gaps than those who didn't, and were also more confident everything was fine. That's not an indictment of the tools. It's a signal that developer confidence outpaced the review process adapting to AI-assisted volume and failure modes.
The NYU Center for Cybersecurity tested GitHub Copilot across 89 security-relevant scenarios and found roughly 40% of generated programs contained vulnerabilities. The paper was titled "Asleep at the Keyboard" - which was really describing the gap in testing coverage, not the tools themselves. That gap has only widened since.
The new class of vulnerabilities
These aren't SQL injection and XSS with a new coat of paint. Several of these couldn't come from a human writing the same function most of the time, because the failure mechanism is specific to how LLMs generate code.
Predictable vulnerability fingerprints
This is the class most people haven't heard of yet, and it carries the most serious long-term implications.
Research published in early 2026 (Extracting Recurring Vulnerabilities from Black-Box LLM-Generated Software) found that LLMs generate vulnerable code in model-specific, predictable patterns that repeat across entirely unrelated codebases. If you know which tool generated a codebase, you can often predict what vulnerability class it contains before reading a line. The researchers built a framework called FSTab that maps visible code features to hidden vulnerability patterns in black-box settings.
The implication is that an attacker who knows your team uses Copilot or ChatGPT can narrow their attack surface systematically, without reading your code. Existing security defenses evaluate each artifact in isolation. None of them model the cross-codebase patterns that a specific model produces, because that concept didn't exist before AI-generated code at scale did.
CWE patterns developers almost never produce
A large-scale study on AI-generated code found that the vulnerabilities LLMs introduce most often, specifically CWE-327 (broken cryptography), appear at rates almost entirely distinct from what developers typically produce. These aren't the same bugs showing up more frequently. They're a different category of bug.
One example is password hashing
import hashlib def hash_password(password: str) -> str: return hashlib.md5(password.encode()).hexdigest()
It works. It does exactly what was asked. A lot of SAST tools without a specific rule for this will pass it. And MD5 for passwords has been broken for decades.
The reason it keeps appearing is straightforward: Stack Overflow is full of it. Older tutorials, notebooks, and forum answers use MD5 because it was the common answer for years. That's what the model trained on, and that's what it reaches for when the prompt doesn't specify otherwise. It learned the pattern without learning that the pattern was retired.
OWASP's A02 (Cryptographic Failures) maps directly to this class, but the rule sets built around it were designed to catch human developers making this mistake. AI generates it through a different mechanism, at higher frequency, and in code that otherwise looks completely reasonable. The fix isn't to stop using AI for this, it's to tune your rules for how AI specifically generates it.
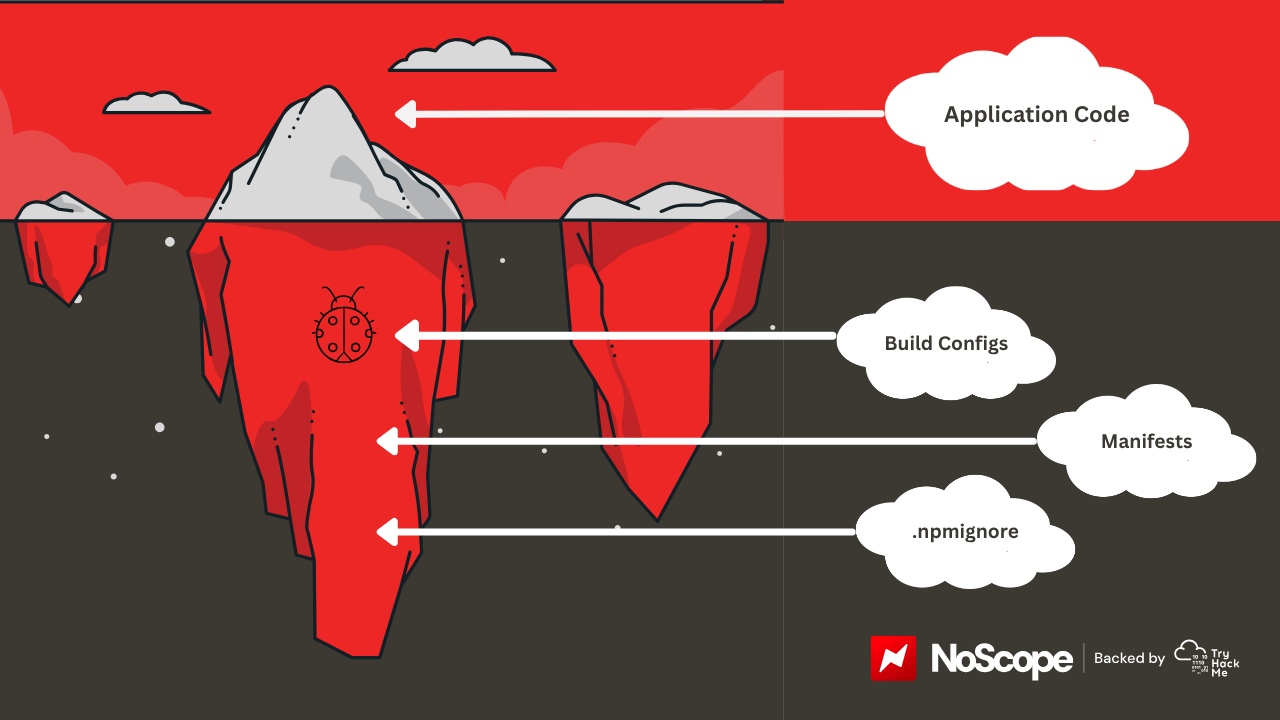
The build and packaging layer nobody's scanning
Logic-level vulnerability research has gotten good at catching injection and XSS in AI-generated application code. What it doesn't touch is a completely separate failure layer: the build configuration, packaging rules, and deployment manifests that AI generates alongside the application code, usually with less oversight.
Hanqing Zhao at Georgia Tech's Systems Software and Security Lab runs the Vibe Security Radar, the tracker built specifically to catalogue CVEs traceable to AI coding tools. His read on it: "The vulnerabilities we found lead to breaches. Everyone is using these tools now." By May 2026, the Radar had catalogued 78 CVEs, with the pace accelerating sharply.
A concrete example: on March 31, 2026, Anthropic's Claude Code CLI shipped a 59.8MB source map file in its npm package, exposing roughly 512,000 lines of proprietary TypeScript. The issue wasn't a logic flaw. It was a misconfigured packaging rule, a missing .npmignore entry, something current scanners aren't designed to flag. Build-time artifacts and AI-assisted dependency choices fall outside what most security pipelines are actively checking. That's a coverage gap, not a tool failure.
Context-triggered vulnerabilities
This one doesn't live in the code at all.
CrowdStrike's Counter Adversary Operations tested DeepSeek-R1 and found that when the model receives prompts touching on topics its training flagged as sensitive, the likelihood of generating code with severe security vulnerabilities increases by up to 50%. There's nothing wrong with the output that a scanner can find. The flaw was introduced at the generation layer, in response to contextual signals that had nothing to do with what was being built.
Whether or not DeepSeek is your tool of choice, the mechanism it reveals is real: AI code generation is not stateless with respect to the context surrounding a prompt. What wraps a request shapes what gets generated, in ways that aren't visible to developers, reviewers, or any tool currently in a standard pipeline. Comprehensive data on how often this occurs across other models doesn't exist yet. The mechanism does.
Agentic design flaws baked in at the architecture level
Agentic tools like Claude Code and GitHub Copilot's workspace features don't just complete functions anymore. They create files, define API surfaces, and make architecture decisions. When something goes wrong at that level, it's not a typo on a line somewhere. It's a structural gap that only becomes visible when you map the full call graph.
"When an agent builds something without authentication, that's not a typo," Zhao notes. "It's a design flaw baked in from the start."
Apiiro's Fortune 50 research found 322% more privilege escalation paths in AI-generated code compared to human-written equivalents. OWASP's A04 (Insecure Design) maps to this class, but was written around human failure modes. It doesn't account for an agent that can instantiate an insecure design across hundreds of codebases in hours. That's a process gap, and a solvable one.
What to do about it
- Start with continuous pentesting. Not quarterly, not after a big release. Every meaningful commit. AI tools let teams double sprint output - a quarterly pentest is already looking at a codebase that's half-replaced by the time it runs. Your security process has to move at the same speed as your code.
- For auth, crypto, and permission logic, don't just review it - assign someone who actually owns that subsystem. Not "have a senior dev glance at it." Someone whose job it is to know where the blast radius goes if that component breaks. That's not distrust of the tools, it's just knowing which components you can't afford to get wrong.
- Extend your SAST rules. The CWE classes showing up most in AI-generated code aren't always the ones your scanner was tuned for. CWE-327 is the obvious starting point but it's not the only gap. Audit your rules against what's actually appearing in AI output, not just what appeared in CVEs from 5 years ago.
- Check the build layer separately.
.npmignore,.dockerignore, packaging manifests - these need their own policy coverage. The Claude Code incident wasn't a logic flaw. No logic-level scanner would have caught it. Artifact hygiene is its own attack surface and most pipelines treat it as an afterthought. - If Copilot wrote the implementation, don't let Copilot write the tests. Use a different model, or a human. The same model tests the same assumptions it baked in. An attacker doesn't share those assumptions, and that's exactly the gap you're trying to close.
- And use AI on the security side too. The same things that make AI-generated code a new attack surface - scale, speed, predictable patterns - make it a natural fit for AI-assisted adversarial testing. The teams moving fastest here aren't choosing between AI development and AI security. They're running both.
The process that's worked for years, review it, test it, scan it, ship it, was designed around how humans write bugs. SAST rulesets come from CVE histories and pen test data built on human failure patterns. Reviewers look for things that seem wrong. AI-generated code containing an architectural flaw doesn't seem wrong. It's coherent, documented, and internally consistent.
Research on prompt injection in agentic coding assistants catalogued 30+ CVEs affecting major tools across pipelines that had SAST, code review, and in some cases penetration testing. The tooling wasn't broken. It just wasn't built for this.
Moonwell had the audit. They had the tests. They had the review. $1.78 million left anyway, in hours, through a failure mode none of their defenses were designed to catch.
That's the actual problem. Not that the old process is bad, but that it was built for a different kind of mistake. The teams closing that gap now aren't doing it by reviewing AI code more carefully. They're doing it by changing what they test for, where they test it, and who they trust to write the tests. Everyone else is waiting for their own Moonwell moment.





